
Introduction
In the previous post I covered Entity Relationship Models (ERM); and we looked at the Lesson_005 files in the learning-data-science GitHub repository to see an example of how to turn an ERM into a SQL script to create the database structure expressed in the ERM. In this post, Lesson 006, we’ll learn about SQL statements, write a simple SELECT statement, and run a series of SQL statements strung together in a SQL script to update my_first_database to match the ERM we developed in the previous lesson. Since data analysis and management are best learned by doing, the objective of this and future posts is to get readers hands on experience using PostgreSQL and R.
This lesson builds on earlier posts so, if this is your first time reading this blog and you’d like to follow along on your computer, then please go back and start from the post Learning Data Science and work through the lessons up to this point. For this post we’ll refer to files in the Lesson_005 and Lesson_006 folders in the learning-data-science repository. If you have not already forked the learning-data-science repository, and cloned the fork to your computer, please do so now following the instructions provided in the post Learning Data Science. If you have previously forked and cloned the repository, but don’t have the files for this lesson, then follow the instructions here to update your fork with the latest files.
Running into issues?
As always, if you have any issues accessing the files in the learning-data-science repository or encounter errors running the SQL files I’ve provided please feel free to contact me using the form on the Contact page.
If you are not familiar with version control using Git and GitHub, I recommend going back and working through the hands on tutorials in my series on version control starting with “Version Control: An Overview.”
SQL Statements
SQL statements are a combination of commands (e.g., SELECT), clauses (e.g. FROM), and expressions (e.g. column1 >= 100) that perform a database action. Using the SELECT command to query a database table to view the data within is an example of a SQL statement. For example:
SELECT
column1, column2, column3
FROM table1
WHERE column3 >= 100
ORDER BY column3 ASC;In the above select statement, SELECT is the command; FROM, WHERE, and ORDER BY are clauses, and the remaining items are expressions.
SQL statements are used to query data, update data, insert data into tables, delete data, and alter the database structure, among other actions.
Commands
Commands specify the action that you wish to perform on the database. Commonly used commands are SELECT, UPDATE, INSERT, and DELETE. A complete list of SQL commands supported by PostgreSQL is here: SQL Commands.
Clauses
Clauses are used with commands to customize the outcome of the database action. Commonly used clauses include FROM, JOIN, WHERE, and ORDER BY.
Expressions
Expressions are used with commands and clauses and are any combination of tables, columns, operators or functions, conditions, or formulas that evaluate to a value. PostgreSQL recognizes 3 general types of expressions: table expressions, value expressions, and conditional expressions. In the above code example the references to columns are value expressions, the reference to table1 after the FROM clause is a table expression, and the expression after the WHERE clause is a special type of value expression called a boolean expression. Boolean expressions evaluate to true/false, and in the above example the query will only return those rows in which the condition evaluates to true (i.e., the rows in table1 for which the value of column3 is greater than or equal to 100).
SELECT Statement
Next we’ll write a simple select statement to query data from my_first_database. To begin, open pgAdmin on your computer, connect to my_first_database, and open the Query Tool. Let’s say that we are interested in which plots in the public.sample table occur at an elevation greater than or equal to 1000 meters. To select the plots that meet this elevation criteria we could write the following select statement.
SELECT
study_value,
sample_id,
elevation_m
FROM public.sample
WHERE elevation_m >= 1000
ORDER BY elevation_m ASC;This is a basic select statement in which we are specifying that we want 3 columns returned from the public.sample table. In addition we only want those rows returned for which the elevation_m column is greater than or equal to 1000 meters and we want the results returned in ascending order by elevation_m. Copy the above code into the Query Tool and click the Execute button.
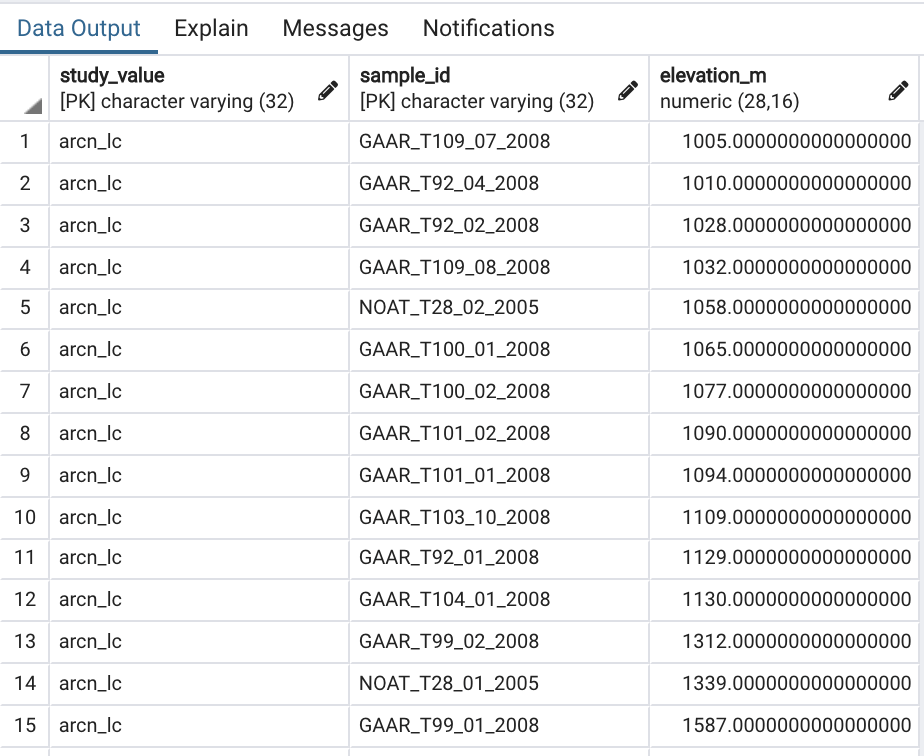
The results of the query are displayed in Figure 1. A total of 15 plots have an elevation greater than or equal to 1000 meters. The lowest elevation plot was located at an elevation of 1,005 m, and the highest elevation plot was located at an elevation of 1,587 m. In the next lesson I’ll cover SELECT statements in more detail.
Implementing the Entity Relationship Model
SQL Scripts
A SQL script is a text file with a .sql extension that contains one or more SQL statements. If a SQL script contains more than one statement, then each statement is separated by a semicolon. An example of a SQL script with multiple statements is in the Lesson_005 folder in the learning-data-science GitHub repository.
In the previous lesson we looked at the SQL file create_tables_script_for_my_first_db.sql which contains the the SQL to create the tables, primary keys, and foreign key constraints from the ERM that we developed for my-first-database. The code block below shows the first and last few lines of the script, and shows multiple statements separated by semicolons.
BEGIN;
-- Creating tables
CREATE TABLE IF NOT EXISTS public.site
(
unique_id serial,
study_value character varying(32),
sample_id character varying(32),
site_start_ts timestamp with time zone,
site_observer_value character varying(32),
physiography_value character varying(32),
geomorph_value character varying(32),
microtopo_value character varying(32),
soil_restrict_layer_code character varying(32),
depth_to_restrict_layer_cm numeric(28, 16),
water_table_depth_cm numeric(28, 16),
site_ph numeric(28, 16),
site_ec_us_cm numeric(28, 16),
slope_percent numeric(28, 16),
aspect_degrees numeric(28, 16),
surface_organic_thick_cm numeric(28, 16),
depth_to_gt_fifteen_pct_frags_cm (28, 16),
site_field_note text,
site_office_note text,
PRIMARY KEY (study_value,sample_id)
)
WITH (
OIDS = FALSE
);
CREATE TABLE IF NOT EXISTS domains.dom_physiography
(
unique_id serial,
sort_order integer,
data_value character varying(32),
label character varying(255),
definition text,
note text,
PRIMARY KEY (unique_id)
)
WITH (
OIDS = FALSE
);
.
.
.
ALTER TABLE IF EXISTS public.vegetation
ADD FOREIGN KEY (veg_community_value)
REFERENCES domains.dom_veg_community (data_value)
NOT VALID;
END; -- commits the current transactionRunning the Scripts
In pgAdmin open a Query Tool and then open the create_tables_script_for_my_first_db.sql script from the Lesson_005 folder in your local repository. The script contains a variety of SQL statements that will create tables, alter tables to add foreign key relationships, and add comments to columns.
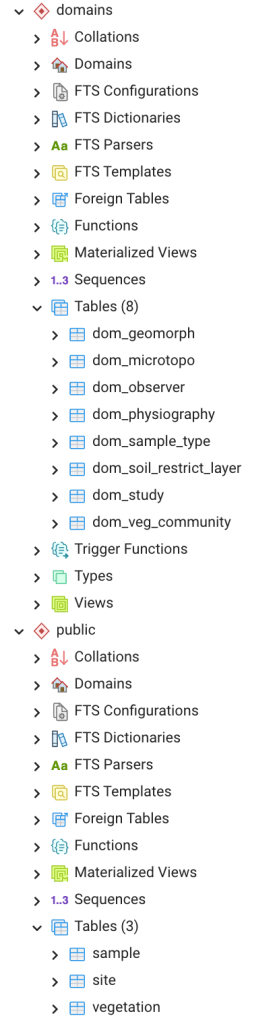
Next, click the Execute button to run the script. Once the script has run look at the browser on the far left side of the main pgAdmin window. The tables should look like those in Figure 2. There are now 8 tables in the domains schema and 3 in the public schema. The database structure now matches the My First Database Entity Relationship Model that we developed in the previous lesson.
Inserting Data
The next step is insert data into the newly created tables using the scripts in the Lesson 6 folder. We’ll need to begin by inserting the data into the domain tables. This is because of the foreign key relationships that we created between public.site and public.vegetation tables and the tables in the domains schema.
Domain Tables
In pgAdmin open a Query Tool and then navigate to the Lesson_006 folder in your local repository. Open the 01_insert_into_domains.sql script. The script contains multiple insert statements, one for each of the newly created domain tables. For more on insert statements see Lesson 003: Inserting Data into a Table. Notice that I started the script with BEGIN, all statements are separated by semicolons, and I finished the script with END. I also included COMMIT after each statement, but I’ve commented those out. This is because you could use the script to copy each statement into the Query Tool and run each separately. This could be useful for debugging the script if you encountered errors.
This brings up an important point which is that you should be careful using scripts with multiple statements. You should really only use them if you 100% certain your code is correct since there is no way to check the outcome of each statement (for instance using RETURNING) without running each separately. To confirm the insert worked correctly open each table in pgAdmin by right clicking on a table and choosing View/Edit data. For instance, the domains.dom_physiography table shown in Figure 3.
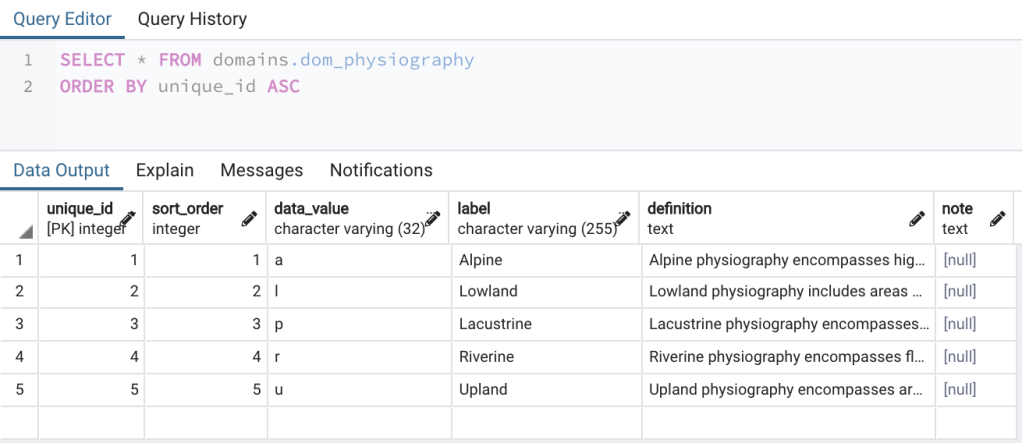
Note that I’ve included a definition for each class in the domains.dom_physiography table. It’s a good practice to include a definition for each class in a domain table. However, if you look at the other newly created domain tables you’ll see that I’ve not included definitions in any of them. This is only to save time preparing this blog post and is not recommended in practice.
Public Tables
Now that the data has been inserted into the domain tables now we can insert the data into the public tables. To do so open the 02_insert_into_site.sql script using the Query Tool and execute it. Since I started the script with BEGIN and ended it with RETURNING you should see 759 rows returned (Figure 4). Please be sure to click the Commit button to save the data to the database and finish the transaction.

Lastly, run the 03_insert_into_vegetation.sql script. Similar to the public.site table you should see 759 rows returned. Click the Commit button to save the data to the public.vegetation table in my_first_database.
Recommended Reading
As a supplement to this post, I encourage you to read about the 3 general types of expressions recognized by PostgreSQL: table expressions, value expressions, and conditional expressions.
Next Time on Elfinwood Data Science Blog
In this post, we learned about SQL statements, ran several SQL statements strung together in a SQL script to update my_first_database to match ERM we developed in the previous lesson, and wrote a basic SELECT statement. In the next post we’ll go into more detail on SELECT statements to learn how to query the data in my_first_database in various ways.
If you like this post then please consider subscribing to this blog (see below) or following me on social media.If you’d like to follow this blog, but you don’t want to follow by subscribing through WordPress then a couple of options exist. You can “Like” the Elfinwood Data Science Blog Facebook Page or send me your email using the form on the Contacts Page and I’ll add you to the blog’s email list.
Follow My Blog
Copyright © 2021, Aaron Wells

One thought on “Lesson 006: SQL Statements”