
Introduction
In the previous post I covered branches and basic merging in Git. In this post I’ll introduce readers to a GitHub repository that we’ll be using for this and future posts to facilitate learning, and then you’ll fork the repository and clone the forked repository to your computer. Since data analysis and management are best learned by doing, the objective of this and future posts is to get readers hands on experience using PostgreSQL and R. If you are not familiar with version control using Git and GitHub, I recommend going back and working through the hands on tutorials in my 5 part series on version control starting with “Version Control: An Overview.”
Learning Data Science GitHub Repository
The learning-data-science GitHub repository is for learning data analysis and management in association with the Elfinwood Data Science Blog. Using the repository I’ll share files with you, the readers of this blog, to use in conjunction with the lessons in future blog posts. The lessons will be hands on, and each will build on lessons from earlier posts, so if you really want to use this blog to learn, then please follow along on your computer. If you have questions or get stuck along the way please either leave a comment in the comment block at the bottom of the page that you’re stuck on, or contact me using the form on the Contact page.
Forking a Repository on GitHub
To use this repository to learn data analysis and management while following the related lessons on the Elfinwood Data Science Blog I recommend that you fork this repository on GitHub, and then clone the fork locally. In the previous post I covered the differences between clone, branching, and forking a repository. You’ll recall that forking is the process of creating a working copy directly on the remote end of things, for instance in GitHub or GitLab. Forking is similar to cloning. However, a “fork” is a separate, distinct, stand alone copy of a repository that is indirectly related to the original repository through the pull request and merge cycle.
A “fork” is a separate, distinct, stand alone copy of repository that is indirectly related to the original repository through the pull request and merge cycle.
To fork the learning-data-science repository on GitHub follow these steps:
- Go to https://github.com/elfinwood-data-sci/learning-data-science
- Sign in to your GitHub account. If you don’t have a GitHub account, then create one here.
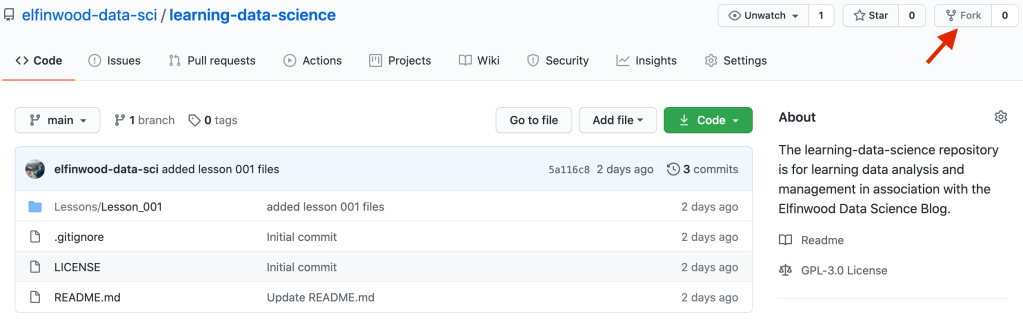
- Click the “Fork” button in the upper right hand corner of the screen (Figure 1, red arrow)
- A fork of the learning-data-science repository will be created in your account.
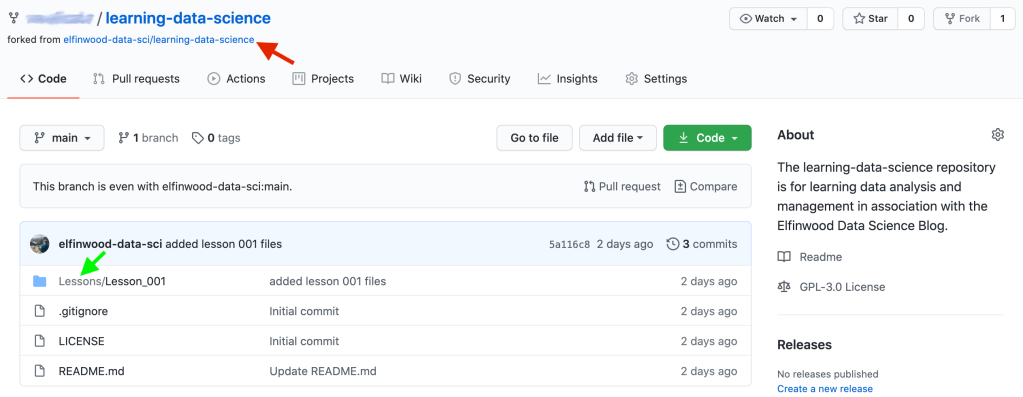
Your GitHub account page should look similar to Figure 2. It will look very much like the learning-data_science repository at the elfinwood-data-sci GitHub page, with the exception that your username will be in the upper left corner of the page followed by “/learning-data-science.” Note that GitHub provides a link to the original source of the fork directly beneath the repository title (Figure 2, red arrow).
Cloning the Forked Repository
If you are familiar with version control, or followed along through my 5 part series on version control, then cloning a repository will be second nature for you. If you are not familiar with version control and did not follow along through my series on version control then I recommend pausing here and going back and working through the hands on tutorials in my 5 part series on version control starting with “Version Control: An Overview.” Remember that in this case you are cloning your fork of the learning-data-science repository.
To clone your fork of the repository follow the same steps that you would use to clone any other repository as described in this post: Getting Started with Version Control.
Using the Learning Data Science Repository with this Blog
The learning-data-science repository is designed to be used with this blog to help you learn data science. In future blog posts I’ll provide lessons on data analysis and management, and will provide you with files related to each lesson through the learning-data-science repository. I’ll also provide you with a small dataset to use to work through the lessons. I’ve recommended that you fork the learning-data-science repository so that you’ll have your own stand-alone copy of the repository that is indirectly related to the my learning-data-science repository through process of syncing.
In a future post I’ll show you how to configure your fork such that you can periodically sync it with my learning-data-science repository. By periodically syncing your fork with my repository you’ll be able to get the most recent lesson files from the learning-data-science repository. For this to work most effectively, it’s best if you don’t modify the folder structure or any files that I provide in the “Lessons” folder (Figure 2, green arrow). Instead, use the files I provide as instructed in each respective blog post.
Further, I recommend that you create your own separate repository for managing your own files. I also recommend that you use the skills that you learn from this blog and apply them to your own dataset. Perhaps you’re an undergraduate or graduate student with your own research dataset, or you’re a professional managing datasets for your university, agency, or clients. Whatever the case may be, applying what you learn in this blog to a real world dataset that you’re managing will dramatically improve your proficiency managing and analyzing data.
What I Bring to the Table
Here’s what I’ll provide:
- Lesson files available in the learning-data-science GitHub repository.
- Blog posts and new files for each lesson released once a month
- Each lesson will cover a topic in data science, with instructions on how to use the lesson files from the learning-data-science repository
- A small dataset to use along with the lesson files and blog posts.
- An advertisement free website so you can focus on learning data science rather than dealing with annoying popup windows and ads flashing on the side of the page.
What You Need to Bring to the Table
Here’s what you need to do:
- Follow along with the lesson plans on your computer, starting with the instructions in this post to fork the learning-data-science GitHub repository
- Have a willingness to learn and work through the challenges along the way
- Contact me with questions or if you notice something that’s not working
- Optionally, apply what you learn in the lessons to your own dataset.
- Optionally, subscribe to this blog, follow this blog on social media, or signup for the email list by contacting me
- Optionally, share this website with your friends or others who you may think would benefit from it.
Recommended Reading
As a supplement to this post, I encourage you to read the GitHub docs on forking a repository through step 2 of the section “Keep your Fork Synced.”
Next Time on Elfinwood Data Science Blog
In this post I introduced readers to a GitHub repository that we’ll be using for this and future posts to facilitate learning, walked readers through forking the repository, and discussed how to use the repository with this blog to learn data science. In the next post, we’ll create a PostgreSQL database server and a database using pgAdmin.
If you like this post then please consider subscribing to this blog (see below) or following me on social media. If you’d like to follow this blog, but you don’t want to follow by subscribing through WordPress then a couple of options exist. You can “Like” the Elfinwood Data Science Blog Facebook Page or send me your email using the form on the Contacts Page and I’ll add you to the blog’s email list.
Follow My Blog
Copyright © 2020, Aaron Wells

7 thoughts on “Learning Data Science”